Language models don’t treat all languages equally and the imbalance starts earlier than most people think.
Before a model generates a single word, attends to context, or produces an embedding, it performs one simple step: tokenization. This step quietly determines how text is broken down into units the model can understand. And as it turns out, this process introduces measurable disparities across languages.
We revisit the paper “Language Model Tokenizers Introduce Unfairness Between Languages” and reproduce its core ideas across modern tokenizers including Tiny-Aya, Qwen3, Gemma3, and Meta.
From Text to Embeddings: Why Tokenization Is Not Boilerplate
Every language model follows the same pipeline:
Raw text → Tokens → Token IDs → Embeddings
"Hello world" → ["Hello", "world"] → [9906, 1917] → [[0.2, -0.5, ...], ...]-
Tokenization: text is split into subword units against a fixed vocabulary budget (typically 32k–262k entries). Every input must be expressible within that vocabulary. For example:
"unbelievable"→["un", "believ", "able"]. -
Token IDs: each token maps to an integer index via a lookup table:
"Hello"→9906,"world"→1917. -
Embeddings: each token ID retrieves a vector from an embedding matrix of shape
(vocab_size, embedding_dim). For Llama 3.1 that’s(128000, 4096), so token9906maps to a 4096-dimensional vector.
How that vocabulary budget is allocated across scripts and languages is the central variable in tokenization fairness. A language with poor vocabulary coverage has words fragmented into many subword pieces, or collapsed into a generic [UNK] token, one vector for all unknowns, carrying no semantic specificity. The model cannot distinguish between words that share a representation. This means more tokens per sentence, worse semantic representation, and poorer downstream performance before training even begins.
Tokenizer vocabulary allocation directly determines embedding quality, which determines model capability for every language, before training even begins.
Tokenization Algorithm Taxonomy
Start with individual characters, then greedily merge the most frequent adjacent pair repeatedly until the vocabulary budget is exhausted. The resulting vocabulary directly reflects corpus frequency. If 90% of training data is English, English subwords get merged aggressively while rare-language characters stay fragmented at the character level.
Like BPE but selects merges by maximizing corpus likelihood. It picks the pair that maximizes P(AB)/P(A)P(B) rather than raw frequency. The ## prefix marks mid-word continuations, making word boundaries explicit: "embedding" → ["em", "##bed", "##ding"]. More principled than frequency, still biased by training data composition.
Works directly on raw Unicode without whitespace pre-tokenization, treating spaces as just another character (▁). Essential for languages like Chinese, Japanese, and Thai that have no spaces between words. Supports BPE or Unigram internally. The Unigram variant starts with a large vocabulary and prunes it down, the opposite direction from BPE.
BPE applied over raw UTF-8 bytes rather than characters. Eliminates UNK entirely and every possible string is representable. But it bakes in a structural disadvantage before any merges happen: ASCII (English) is 1 byte per character, Greek/Cyrillic/Arabic are 2 bytes, CJK and Indic scripts are 3 bytes. Non-Latin scripts start at a 2–3× disadvantage from the Unicode encoding alone, regardless of training data.
Byte-level BPE shifts the fairness problem without solving it. Disparity moves from vocabulary coverage to encoding width, which is structural to the Unicode standard and cannot be trained away.
The Core Claim: Upstream, Deterministic, Compounding
The paper’s central argument is that tokenization disparity is upstream of everything in the model pipeline. A perfectly trained, perfectly balanced model still inherits the disparity because the input it receives is already unequal.
Tokenization precedes embeddings, attention, and all learned representations. Model improvements downstream don't fix structural tokenizer bias.
Unlike weight-level bias, tokenization disparity is a pure function of vocabulary. It can be computed exactly without running the model.
More tokens → shorter effective context, higher API cost, more attention steps, diluted training signal, degraded embedding quality.
The transformer’s representational unit is the token, not the word, not the morpheme. A word split into 6 tokens requires 6 embedding lookups and compositional reconstruction across 6 attention steps. The same concept encoded as one token gets direct contextual access in a single step.
Three Sources of Tokenization Disparity
Not all disparity is attributable to tokenizer design choices. There are three sources that interact as a cascade.
1. Linguistic Disparity
Some languages are morphologically more complex independent of any tokenizer. Turkish is agglutinative, it stacks morphemes onto a root to build meaning, so a single Turkish word can encode what English needs a full clause to express:
Turkish: "Çekoslavakyalılaştıramadıklarımızdanmışsınızcasına" (1 word)
English: "as if you were one of those we could not make Czechoslovakian" (12 words)Chinese and Japanese logographic scripts carry morpheme-level semantics per character, often giving them an efficiency advantage in meaning-per-token. This is inherent to the language not the tokenizer’s fault and not fixable by vocabulary design.
2. Tokenizer-Specific Disparity
Even after accounting for linguistic differences, vocabulary allocation creates systematic fragmentation for languages the tokenizer was not trained to handle well. If BPE training data is 90% English, English subwords get merged aggressively while less-represented languages remain at the character level. Their subwords never appeared frequently enough in training to survive the merge process.
3. Data Disparity
BPE is frequency-based, and frequency is entirely determined by corpus composition. English Wikipedia has ~6.7 million articles; Yoruba Wikipedia has ~33,000. A language with 200× less training data produces 200× fewer frequent pairs. Its subwords get merged less aggressively and end up with character-level fragmentation at inference, even if the tokenizer algorithm itself is sound.
Low data → poor frequency statistics → fewer BPE merges → smaller effective vocabulary for that language → high fragmentation at inference → high premium. The three sources are not independent: data disparity causes tokenizer disparity, which causes the measured premium. They compound.
The Tokenization Premium Metric
The paper introduces a single, computable metric for tokenization fairness:
premium = n_tokens(language) / n_tokens(English)
# premium = 1.0 → parity with English
# premium = 2.0 → twice as many tokens for the same content
# premium = 5.0 → five times the tokens -> 5× API cost, 5× context consumedA premium above 1.0 has direct, concrete consequences. It means the speaker of that language uses proportionally more of their context window for the same information, pays more in token-based API pricing, requires more attention steps for the model to process equivalent content, and receives degraded embedding quality as words fragment into meaningless subpieces.
Why parallel translations? The metric is measured on FLORES-200, a professionally translated benchmark spanning 200 languages. Using the same content translated into every language controls for what is being said both sides express identical meaning, so token count differences reflect the tokenizer’s behaviour rather than content variation. The limitation is that parallel translations do not control for morphological complexity: Turkish legitimately encodes more morphemes per idea than English, so some premium reflects linguistic structure rather than tokenizer bias. This conflation is discussed further in Limitations.
The UNK problem. A high UNK rate makes the premium metric meaningless. If a language maps 50% of its characters to [UNK], it produces fewer tokens than it should. The tokenizer is silently discarding information rather than representing it. The paper reports only languages with a UNK rate below 10%, ensuring measured premiums reflect genuine tokenization rather than silent data loss. Models that simply do not know a script can appear to have low fragmentation while actually understanding nothing.
Separating tokenizer bias from linguistic structure. The cleanest isolation uses multi-script languages in FLORES+: languages that appear in two different writing systems. Kashmiri exists in both Arabic script (kas_Arab) and Devanagari script (kas_Deva). Since the language, morphology, and semantic content are identical across both forms, any difference in premium isolates script-induced tokenizer bias directly. The linguistic variable is held constant, only the script changes:
# Kashmiri multi-script comparison: same language, different script
# Premium difference = pure tokenizer/script bias, not linguistic complexity
tiny-aya qwen3 gemma3 meta
kas_Arab 2.58× 3.52× 2.39× 1.83×
kas_Deva 3.36× 4.43× 1.96× 1.69×For Tiny-Aya and Qwen3, Devanagari is penalized more than Arabic for the same language, meaning the vocabulary invested more in Arabic subwords than Devanagari ones. For Gemma3 the pattern reverses, suggesting a different vocabulary investment decision. Meta nearly closes the gap entirely with both scripts under 2×, implying more uniform script coverage.
Paper Findings: English-Centric to Byte-Level Models
English-centric models (RoBERTa, GPT-3/4, FlanT5) show the largest and most consistent premiums. Shan has the worst tokenization parity across all four English-centric tokenizers evaluated. Only languages with a UNK rate below 10% are included. Languages above this threshold are excluded because their premium is artificially suppressed by silent data loss rather than genuine tokenization.
Models targeting other languages (ArabicBERT, RoCBert, CamemBERT, GottBERT, BERT Japanese, PhoBERT) all still assign English the lowest premium, even when explicitly trained for a different language. GottBERT (German): English 1.35×, Dutch 1.73×, despite Dutch being more linguistically similar to German than English is. CamemBERT (French): English has the lowest premium at 1.20×. This asymmetry is consistent across the board. The exceptions are RoCBert (Chinese) and BERT Japanese, where the target language achieves near-parity, likely because Chinese and Japanese characters require their own dedicated vocabulary slots that English does not share, forcing genuine script coverage.
Multilingual models (XLM-R, NLLB, M2M100, mT5, BLOOM) improve substantially over English-centric tokenizers but still have languages above 2.5×. BLOOM and NLLB are the only models that encode all 200 FLORES-200 languages with less than 10% UNK: BLOOM via byte-level BPE, NLLB via training on the same 200 languages it evaluates on. XLM-R is measurably closer to parity than the RoBERTa tokenizer it is derived from, demonstrating that deliberate multilingual vocabulary design produces real improvements. But no multilingual model achieves uniform parity across all languages.
Byte-level models present a different tradeoff. CANINE (Unicode codepoint-level) gives Chinese a premium of 0.31–0.34x (better than parity) because each character encodes a full morpheme as a single token. But Shan is penalized because its script uses diacritics as separate codepoints, multiplying its token count. ByT5 (UTF-8 bytes) shows premiums ranging from 0.87× (Yue Chinese) to 3.94× (Shan). The Shan penalty is structural and cannot be trained away: every Shan consonant requires 3 UTF-8 bytes, so the encoding standard itself creates the disparity. Byte-level tokenization eliminates UNK but does not eliminate unfairness. It relocates disparity from vocabulary coverage to encoding width.
Experiment Setup
The paper evaluates tokenizers from 2023. Reproducing it means evaluating against tokenizers that have had additional years of multilingual investment. The four models chosen represent different design philosophies:
| Model | Tokenizer | Vocab | Design intent |
|---|---|---|---|
| Tiny-Aya | SentencePiece BPE | 261k | Fairness-focused; language-bucket weighting |
| Qwen3 | Byte-level BPE | 151k | BPE augmented with explicit CJK character entries |
| Gemma3 | SentencePiece + byte fallback | 262k | Large-vocabulary multilingual |
| Meta (NLLB-200) | SentencePiece BPE | 256k | Trained on the same 200 FLORES languages it evaluates on |
Dataset. FLORES+ devtest: professionally translated sentences across 219 languages, ~1,012 sentences per language. Using parallel translations controls for what is being said; only the encoding of identical content varies across languages.
Metric. Per-sentence premium computed as n_tokens(lang) / n_tokens(eng) on aligned sentence pairs, then aggregated (mean, median, std) per language. Languages with UNK rate above 10% are excluded — their premiums are artificially suppressed because the tokenizer is silently discarding characters rather than representing them.
The Core Compute Loop
The full computation fits in a single function. For each (model, language) pair it checks UNK rate, computes per-sentence premium, and aggregates:
def compute(df, tokenizers):
for model_name, tokenizer in tokenizers.items():
for lang in all_languages:
eng_sentences, lang_sentences = get_aligned_pair(df, lang)
# Exclude if tokenizer doesn't know the script
unk = unk_rate(tokenizer, tokenize_all(tokenizer, lang_sentences))
if unk > UNK_THRESHOLD:
records.append({..., "excluded": True, "unk_rate": unk})
continue
# Per-sentence premium
premiums = [
token_count(tokenizer, lang_sent) / token_count(tokenizer, eng_sent)
for eng_sent, lang_sent in zip(eng_sentences, lang_sentences)
if token_count(tokenizer, eng_sent) > 0
]
records.append({
"model": model_name, "language": lang,
"mean_premium": np.mean(premiums),
"median_premium": np.median(premiums),
"std_premium": np.std(premiums),
})Aligned pairs only. The get_aligned_pair function joins English and target-language sentences on sentence ID, dropping any IDs missing from either side. This prevents spurious premium values from mismatched sentence lengths.
No model inference. The computation runs entirely on the tokenizer’s encode function no GPU needed, no forward pass. This is the property the paper highlights: tokenization disparity is measurable without running the model at all.
Language naming. After computing, each ISO code is resolved to a display name via langcodes for readable plots and summaries.
Reproduction Results: Tiny-Aya, Qwen3, Gemma3, Meta
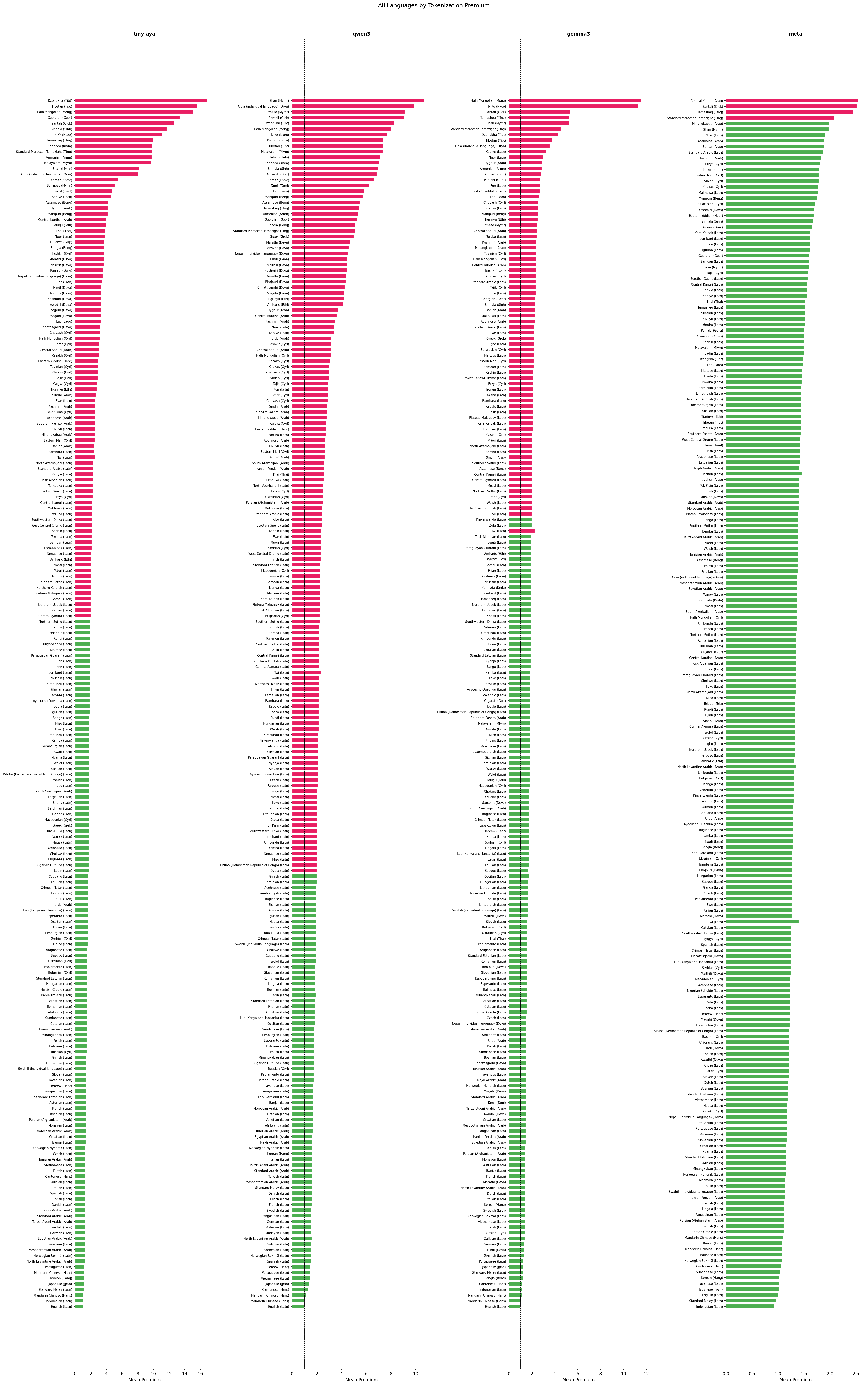
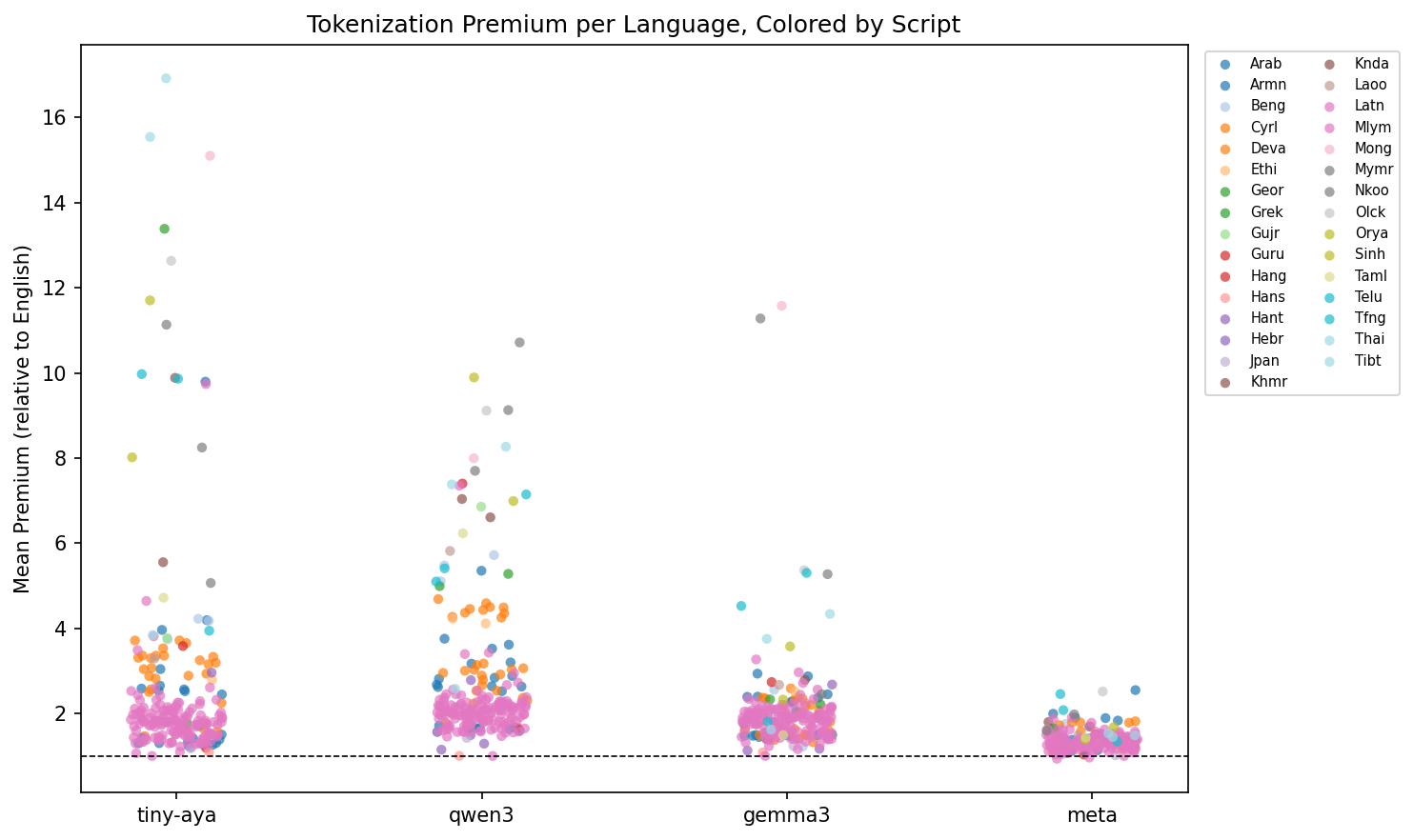
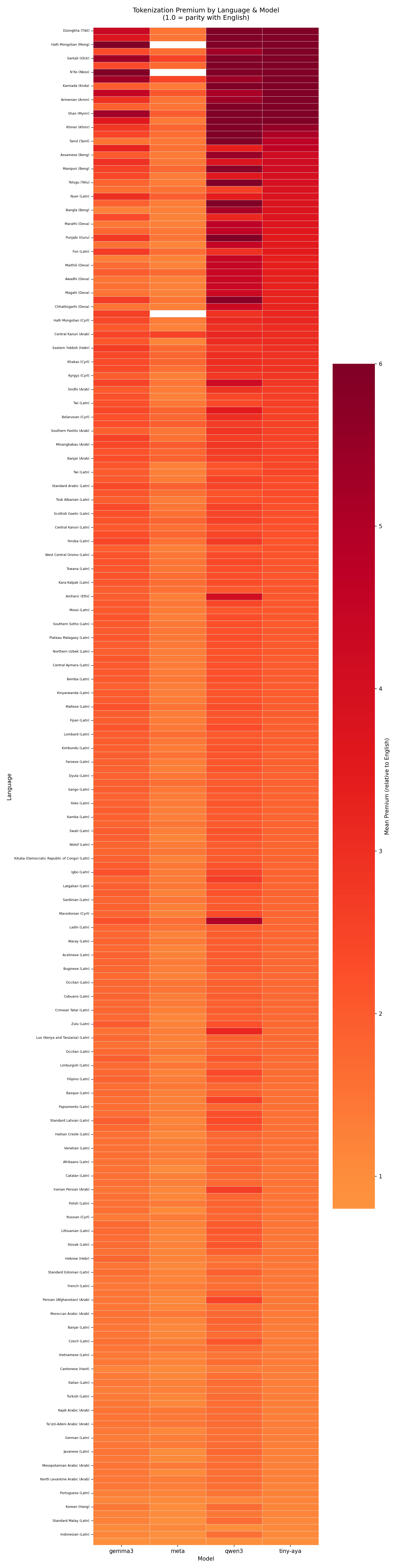
Evaluated on FLORES-200, with ~1,012 sentences per language across 220 languages total.
Tiny-Aya maximum premium: Dzongkha (Tibetan script), the hardest-hit language in our evaluation
Qwen3 maximum premium: Shan (Myanmar script), consistent with the paper's finding on English-centric models
Meta maximum premium: the most compressed distribution across all four models evaluated
Share of Qwen3 languages with premium above 2x, the highest proportion among all four models
Per-Model Narrative
Tiny-Aya was trained with language-bucket weighting, grouping languages by family and script to equalize vocabulary representation. The bimodal result is the signature of this approach: supported languages achieve near-parity (Indonesian 1.06×, Mandarin 1.09×), while excluded scripts face extreme fragmentation (Dzongkha 16.92×, Tibetan 15.55×, Mongolian 15.10×). The boundary is sharp and consequential.
Qwen3 augments its BPE vocabulary with Chinese characters, giving Mandarin the closest result to true parity of any model (1.00×). But the augmentation is script-specific: Shan reaches 10.7×, Oriya 9.9×. The smooth distribution means fewer extreme outliers but more languages stranded in the 3–5× range.
Gemma3 (262k vocabulary) demonstrates the value of raw vocabulary budget. Bengali’s median drops from 4.18× (Tiny-Aya) to 2.04×; Devanagari from 3.36× to 1.52×. Two scripts remain problematic: Mongolian (11.6×) and N’Ko (11.3×), suggesting vocabulary investment is still not uniform.
Meta achieves a distribution unlike the others: median 1.34×, 98.2% of languages under 2×, maximum 2.55× (Kanuri). Japanese reaches 1.02×, Korean 1.03× effectively at parity. This is notable for a model not explicitly marketed as multilingual-first.
Script-Level Medians
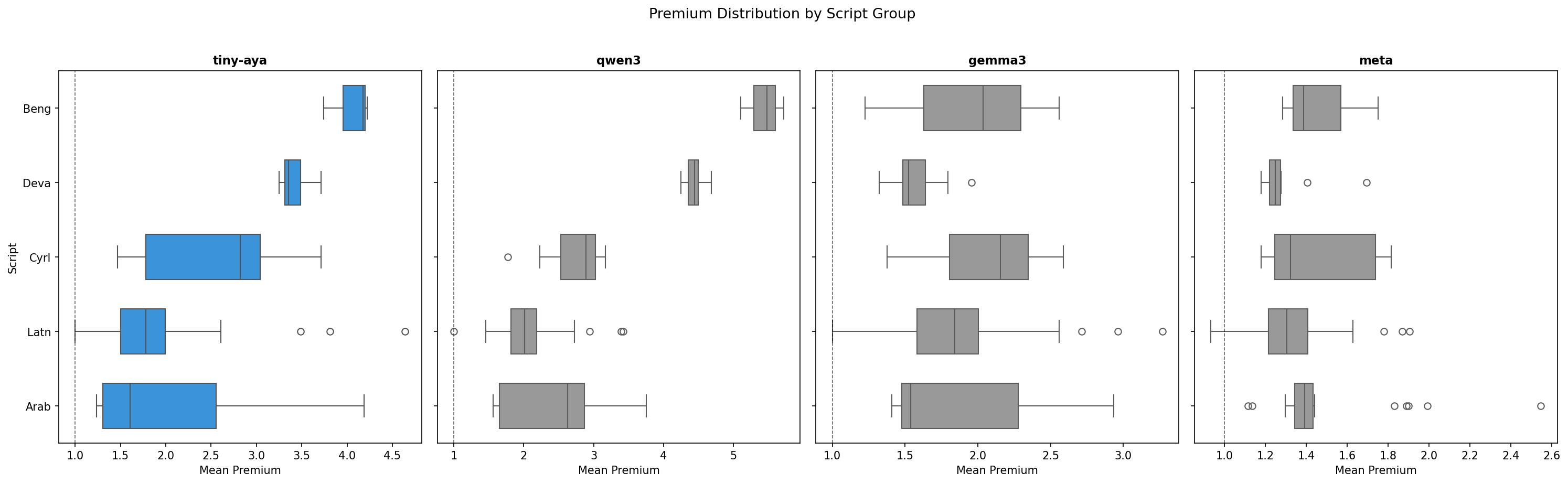
| Script | Tiny-Aya median | Qwen3 median | Gemma3 median | Meta median |
|---|---|---|---|---|
| Bengali (Beng) | 4.18× | 5.48× | 2.04× | 1.39× |
| Devanagari (Deva) | 3.36× | 4.44× | 1.52× | 1.25× |
| Cyrillic (Cyrl) | 2.82× | 2.89× | 2.15× | 1.32× |
| Arabic (Arab) | 1.60× | 2.63× | 1.54× | 1.39× |
| Latin (Latn) | 1.78× | 2.01× | 1.84× | 1.31× |
Cyrillic Variance: An Intra-Script Case Study
Tiny-Aya’s Cyrillic distribution spans 1.47× (Russian) to 3.71× (Bashkir) a 2.5× internal range within a single script. This confirms that script support isn’t binary: vocabulary coverage is concentrated in high-resource Cyrillic languages while minority Cyrillic languages fragment substantially. Meta collapses this variance: Cyrillic median 1.32×, all languages under 1.65×.
Limitations and Open Problems
Tokenization disparity ≠ performance disparity. The paper and this reproduction measure token counts. Neither demonstrates that higher premiums causally reduce task performance. This empirical link is unmeasured.
The premium conflates linguistic and tokenizer-induced disparity. A high premium could reflect agglutination (not the tokenizer’s fault) or poor vocabulary coverage (the tokenizer’s fault). No decomposition methodology is proposed.
English as baseline is question-begging. English’s morphological simplicity and dominant corpus representation make it an atypical reference. A language-agnostic efficiency baseline would be more principled.
No fairness framework. The paper identifies and quantifies the problem without defining what fairness requires: equal token counts? Equal meaning-per-token? Equal downstream performance? These have different implications for tokenizer design.
Research Directions
Decomposing the premium. Multi-script FLORES+ languages (Kashmiri, Uzbek, Serbian) enable direct isolation of script-induced fragmentation from morphological complexity. Combined with WALS typological features, this could yield a principled premium decomposition, the most analytically important open problem the paper leaves open.
Tokenization fairness vs. downstream performance. Measuring premium alongside translation quality, QA accuracy, and summarization across a language-diverse benchmark would establish whether this is a theoretical or practical concern and quantify the effect size.
Understanding Meta’s distribution. Meta’s results suggest near-parity across most scripts is achievable with current methods. The specific vocabulary training decisions producing this distribution are not publicly documented and represent directly actionable knowledge for future tokenizer design.
Tokenization-free architectures. Whether CANINE-style codepoint-level models reduce disparities found in subword models, and whether the sequence length penalty is acceptable for multilingual tasks, remains largely uncharacterized empirically.
Economic fairness. Token-based API pricing means speakers of high-premium languages pay more for equivalent semantic content. Language-normalized pricing, adjusting cost by expected token-per-meaning ratio is a direct downstream application with real-world implications for equitable access to language technology.
Reproduction code available at github.com/nuna-aa/extended-research.
Original paper: Ahia et al., "Language Model Tokenizers Introduce Unfairness Between Languages," arXiv:2305.15425 (2023).
Evaluation uses FLORES-200, 1,012 sentences per language, 220 languages. Premiums computed as mean token count relative to English (eng_Latn_stan1293).