Mechanistic interpretability has produced some of its clearest results in English. The circuits are real, the algorithms are legible, and the attention patterns are interpretable. But as multilingual models become standard infrastructure, a harder question follows: are these circuits shared across languages, or does each language run its own private machinery?
We investigate this question for one of the best-understood circuits in transformer models: the induction head. Using Tiny-Aya, a 36-layer multilingual model, we compare English and Yoruba, a low-resource West African language with distinct morphological structure and substantially less training data. The results reveal a split verdict. The induction circuit is structurally shared. The same heads show the characteristic diagonal attention pattern in both languages. But the causally necessary components differ substantially between the two, with correlation r = 0.273.
The Anthropic Paper: Induction Heads and In-Context Learning
In 2022, researchers at Anthropic published a landmark mechanistic interpretability result: induction heads are the primary source of in-context learning in transformer models. The paper provides six independent lines of evidence linking a specific circuit of attention heads to the model’s ability to learn from context within a single forward pass.
The mechanism works in two steps. The first component, a previous-token head, attends from every position to the position immediately before it. This creates a shifted representation: when the model is at position t, the residual stream encodes information about the token at position t-1. The second component, the induction head proper, uses this shifted information to search backward through the context for a matching pattern. If the current sequence is A B ... A B, the induction head finds the previous A B occurrence and attends to the token that followed it, completing the pattern.
Attention pattern for a repeated sequence [A B C | A B C | A B C]:
A B C A B C A B C
A [ . ]
B [ . . ]
C [ . . . ]
A [ . . . . ]
B [ . . . [*] . ] <- B attends back to previous B
C [ . . . . [*] . ] <- C attends back to previous C
^^^^^^^^
the induction diagonal, offset -(seq_len - 1)The paper identifies a phase transition during training where induction heads emerge abruptly. Before this transition, the model shows modest in-context learning ability. After it, in-context learning improves sharply. The timing coincides exactly with the emergence of the induction circuit, providing a causal link between the two.
This work was done primarily on small, English-trained, attention-only models. What happens in a large multilingual model with grouped-query attention and a vocabulary of 262,144 tokens is an open question.
Setup
Model
We use Tiny-Aya Global (CohereLabs/tiny-aya-global), a multilingual language model trained with explicit fairness objectives across more than 70 languages.
36 transformer layers, 16 query attention heads per layer, grouped-query attention with 4 key-value heads (4 query heads share each KV pair), hidden dimension 2048, vocabulary 262,144 tokens. Total context understanding requires composition across 576 head-slots (36 layers x 16 heads).
It was trained with language-bucket weighting designed to give low-resource languages genuine subword vocabulary coverage. This makes it a meaningful test: if any multilingual model has shared circuits, this one should. It also appeared in the tokenization fairness analysis, giving a direct comparison point for how vocabulary design shapes circuit structure.
Languages
We compare English (eng_Latn) and Yoruba (yor_Latn), drawn from the FLORES+ devtest split. English serves as the reference language with well-understood induction head behaviour from prior work. Yoruba is a tonal Niger-Congo language with approximately 45 million speakers and substantially less web-scale training data than English.
The vocabulary coverage difference is visible immediately in the token pools built from FLORES+ text:
English token pool: ordinary token IDs appearing in FLORES+ English text
Yoruba token pool: 54% fewer tokens, reflecting sparser subword vocabulary coverage for this language
Tokens per test sequence: 25 random tokens repeated 4 times, plus one BOS token prepended
The Yoruba pool is smaller not because Yoruba is simpler, but because fewer of its morphemes appear as dedicated vocabulary entries. Characters with tonal diacritics fall back to byte-level fragments, inflating token counts and shrinking the pool of single-token units.
Sequence Construction
We follow the methodology of Olsson et al. exactly: sample a block of 25 random tokens from the language pool, repeat it 4 times, prepend BOS. The resulting 101-token sequence gives an induction head the perfect test environment. Every token in the last three repetitions has a correct prediction available via pattern lookup.
Induction is measured on the final repetition where the model must rely on in-context pattern matching to perform well.
Research Questions
Do the same attention heads show induction-like diagonal attention patterns in both English and Yoruba, or does each language activate different heads?
Are the same heads causally necessary for induction performance in both languages, or do they diverge when we measure actual impact on model loss?
Does ablating English-specific heads hurt Yoruba and vice versa? This is the strongest test of circuit sharing: not structural similarity, but causal transferability.
Methodology and Results
Induction Scoring: Structural Evidence
For a sequence that repeats a block of length seq_len, an induction head attending at the correct offset attends to the token seq_len - 1 positions back. In the attention weight matrix, this produces a bright stripe along the sub-diagonal at offset -(seq_len - 1). We compute the average attention weight along that diagonal as the induction score for each (layer, head) pair.
We compute this score from Q and K projections directly, because Tiny-Aya uses FlashAttention which does not expose attention weights during a normal forward pass. The score is computed across all sequences per language.
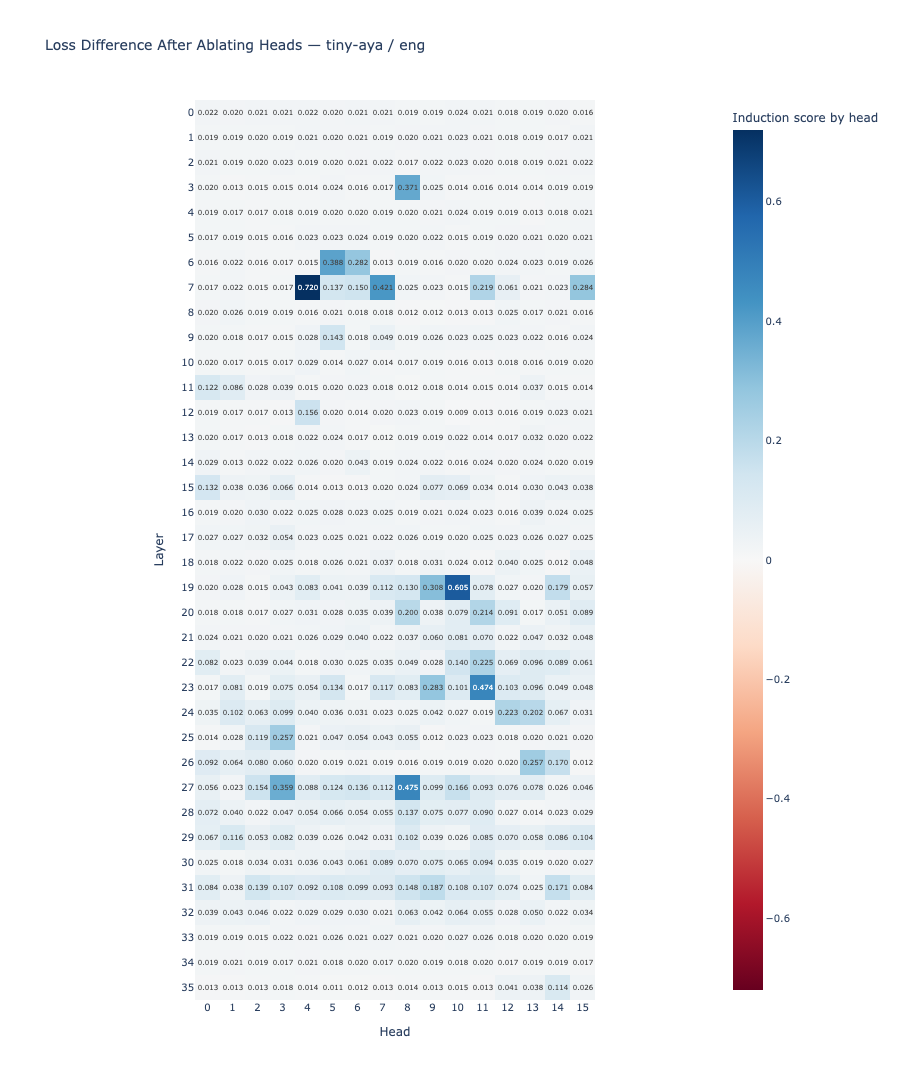
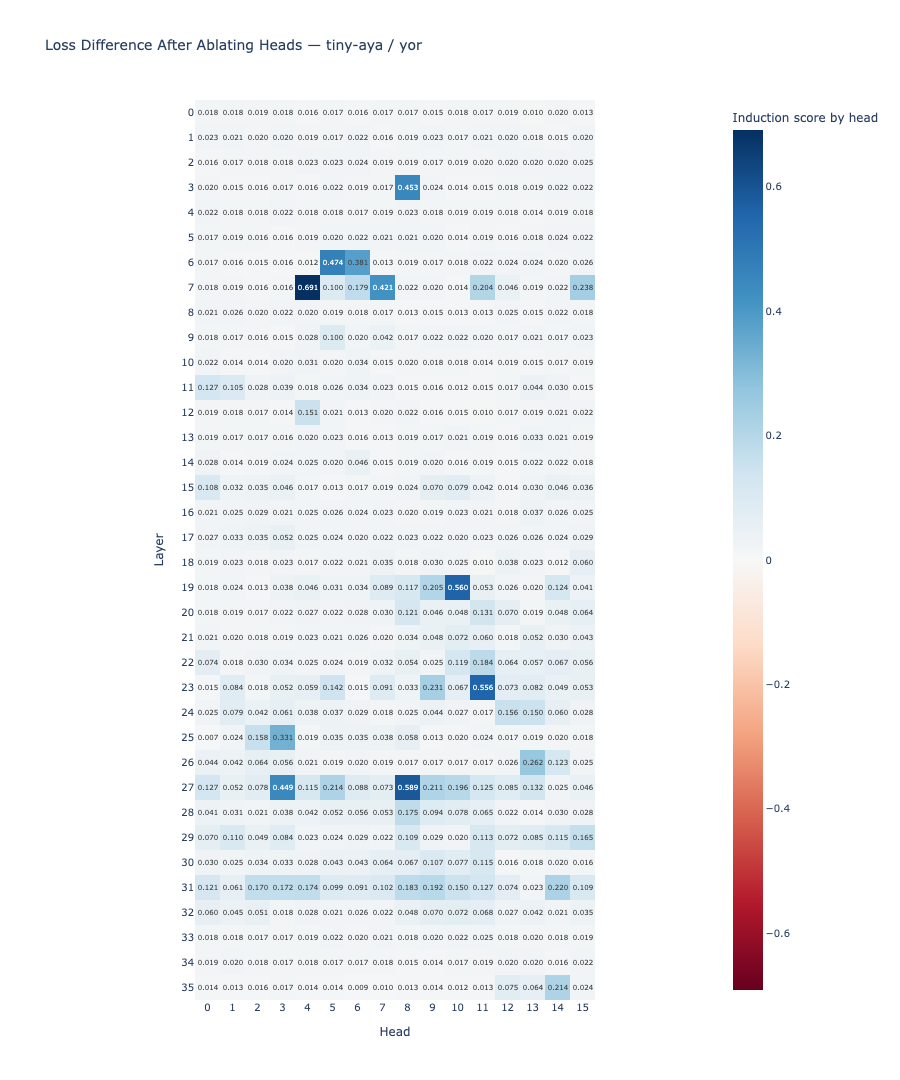
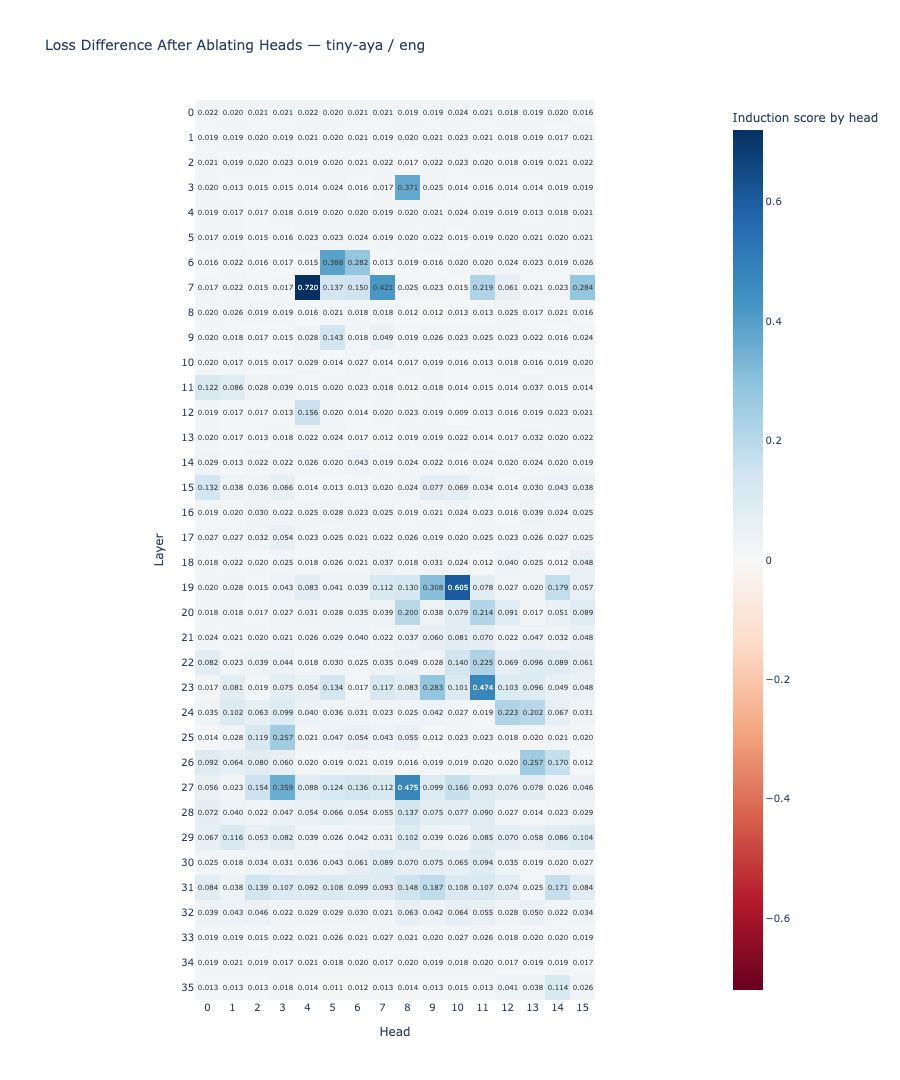
Result: The same heads produce high induction scores in both languages. Layers 7, 19, 23, and 27 contain the highest-scoring heads in both English and Yoruba. English shows 5 heads above the 0.4 threshold; Yoruba shows 8. The shared high-scoring heads include layers 7 (heads 4, 7), 19 (head 10), 23 (head 11), and 27 (head 8).
The induction circuit is structurally shared. The same attention heads produce the characteristic diagonal pattern in both English and Yoruba. This answers RQ1 affirmatively: structural sharing is real and consistent across the two languages.
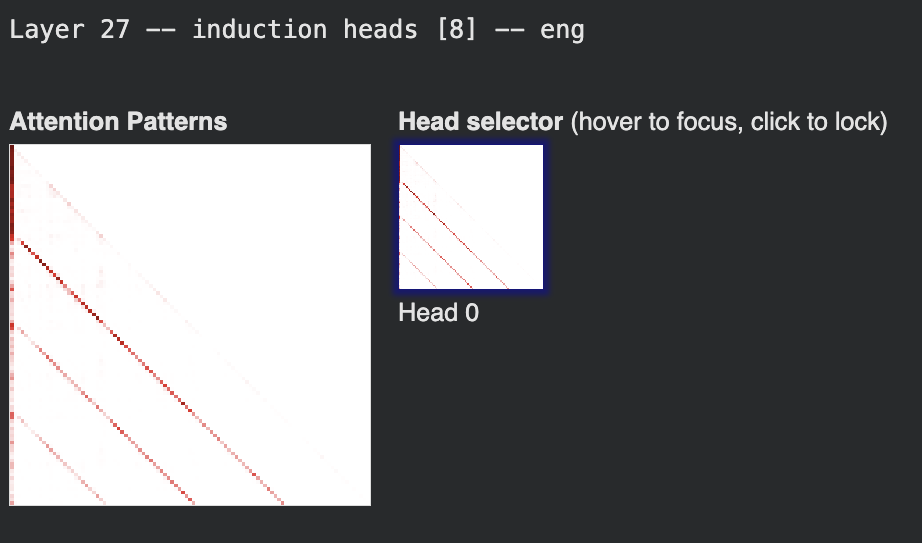
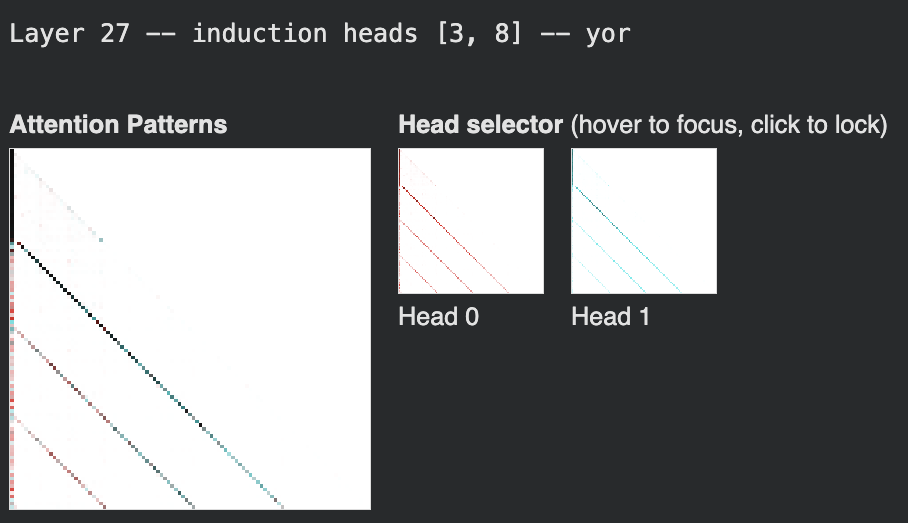
Per-head attention pattern visualizations confirm the diagonal structure directly. For each identified induction head, the attention matrix shows the characteristic sub-diagonal stripe at offset −(seq_len−1) = −24. In English, Layer 7 contains two active heads (4 and 7) both displaying the pattern; Layers 19 and 23 each contain a single dominant head. The Yoruba visualizations show the identical stripe at the same layer-head positions. Layer 27 illustrates both the shared structure and a divergence in head count: English activates one head (head 8), while Yoruba activates two (heads 3 and 8), with head 8 shared between them.
Interactive attention pattern visualisations for all layers are available in the notebook.
Ablation: Causal Evidence
Structural similarity is not the same as causal necessity. A head can show the correct attention pattern without being the component the model actually relies on. To find which heads are causally necessary, we run a zero ablation: for each (layer, head) pair in the 36x16 = 576-head space, we zero out that head’s contribution to the output projection during a forward pass and measure how much loss increases on the final repetition of the sequence.
# Ablation score formula
ablation_score[layer, head] = loss_with_head_zeroed - baseline_loss
# Positive = ablating this head hurt performance = head was doing useful work
# Near zero = head did not matter causallyBaseline losses: English 0.1049, Yoruba 0.1226. The higher Yoruba baseline is consistent with the model having less efficient induction pathways for this language, which the ablation study confirms.
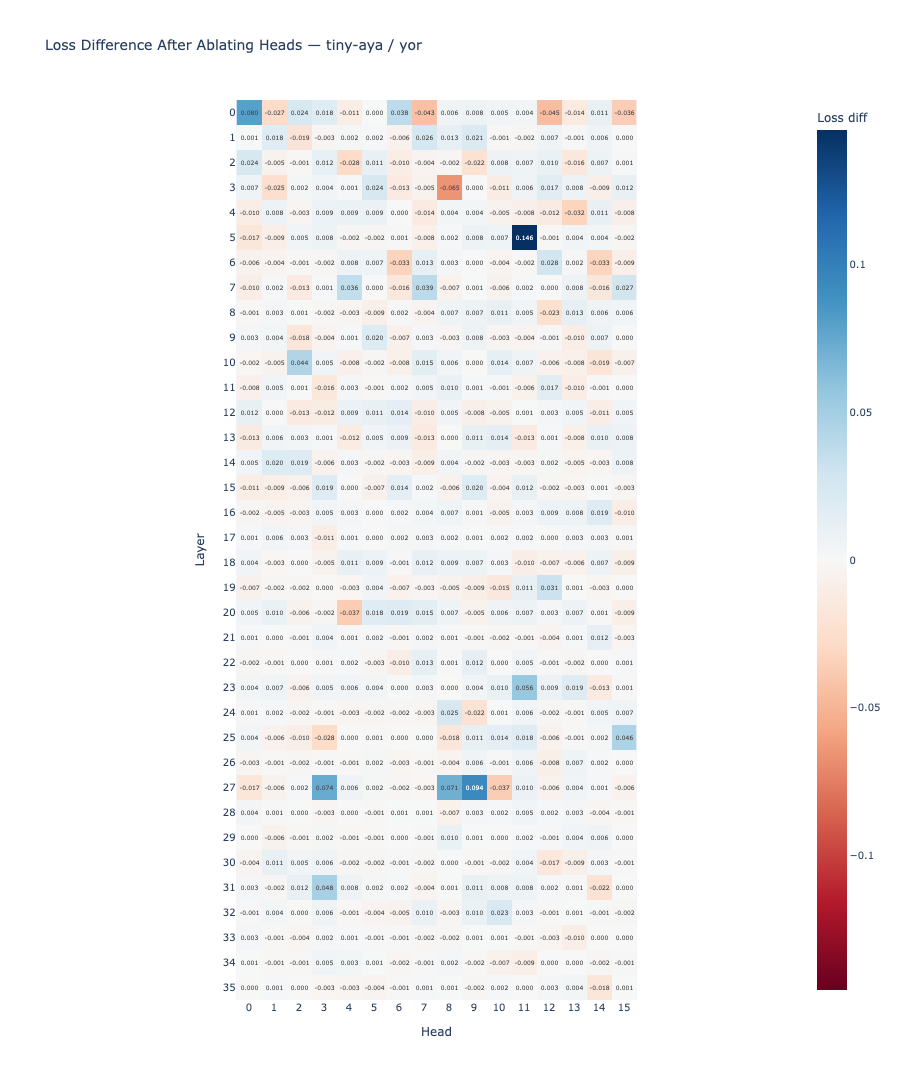
Result: The ablation heatmaps are visually different across the two languages. The correlation between the English and Yoruba ablation score matrices is r = 0.273, indicating weak alignment between which heads are causally necessary in each language.
| Category | Heads (layer, head) | Count |
|---|---|---|
| English helpful (score > 0.05) | (0,5), (0,15), (5,11), (11,12), (31,9) | 5 |
| Yoruba helpful (score > 0.05) | (0,0), (5,11), (23,11), (27,3), (27,8), (27,9), (31,3) | 7 |
| Shared helpful | (5,11) | 1 |
| Overlap | 1 of 11 unique helpful heads (9%) | |
English relies on early-layer heads (layers 0 and 5) as its causal bottleneck, with mid-to-late layer heads (11, 31) serving as secondary contributors. Yoruba relies primarily on mid-to-late heads (layers 23 and 27) as its primary pathway, with the early-layer head (0,0) contributing as well.
Pearson correlation between English and Yoruba ablation score matrices. Weak alignment: the same heads are structurally active but causally language-specific.
Max English ablation delta (head 0,5). Ablating this single early-layer head increases English loss by 0.144 from a baseline of 0.105.
Sum of Yoruba helpful scores vs. 0.417 for English. Yoruba's circuit carries more total causal load per head, with less redundancy distributing the work.
Cross-Language Ablation: Circuit Transfer
The ablation study tells us which heads matter per language. The cross-language ablation asks a stronger question: does ablating English-specific heads hurt Yoruba performance, and vice versa? We ablate all heads in each language-specific group simultaneously and measure the resulting change in loss for the other language.
| Intervention | Impact on target language | Interpretation |
|---|---|---|
| Ablate English-only heads (0,5), (0,15), (31,9) |
-0.019 on Yoruba | No impact. These heads are not part of the Yoruba circuit. |
| Ablate Yoruba-only heads (0,0), (23,11), (27,3), (27,8), (27,9) |
+0.351 on English | Large impact. Layers 23-27 are part of the English circuit as redundant backups. |
| Ablate shared head (5,11) on English | +0.069 | Meaningful loss increase. The shared head contributes to English induction. |
| Ablate shared head (5,11) on Yoruba | +0.157 | 2.3x larger impact than on English. This head is more critical for Yoruba. |
The cross-language ablation resolves an apparent contradiction. The Yoruba-only heads (layers 23-27) affect English strongly when ablated together (+0.351), even though individual ablation of these heads showed small effects. This reveals that layers 23-27 are part of the English circuit, but as redundant backups rather than primary components. English can tolerate losing any one of them individually; it cannot tolerate losing them all at once.
Yoruba has fewer such redundant backups. Its circuit runs through the mid-to-late heads as primary pathways, making each one individually more critical. This is why the shared head (5,11) has 2.3x greater causal impact on Yoruba (+0.157) than on English (+0.069): it is doing primary work in Yoruba but secondary work in English.
The induction circuit is structurally shared but causally language-specific. English has a distributed circuit with early-layer bottlenecks and mid-late redundancy. Yoruba runs the same structural circuit but relies on mid-late heads as primary pathways with less redundancy overall. The shared head (5,11) is the single causally transferable component between the two languages.
Reconciling Structure and Causality
The induction score heatmaps and the ablation heatmaps tell different stories. The same heads light up in both languages structurally. But the heads the model depends on are largely language-specific.
This is not a contradiction. An induction head can implement the lookup algorithm correctly in both languages while the system still routes different amounts of causal load through it. English, with far more training data, may have developed more redundant circuit implementations where multiple heads can each serve as fallback for the others. Yoruba, with less training data and sparser vocabulary coverage, may have developed a leaner circuit where the primary pathway heads carry more of the total load.
Discussion
Why the Bottleneck Differs
Three candidate explanations are consistent with the data.
Tokenization fragmentation. Yoruba’s smaller token pool (2,945 versus 6,424) reflects sparser subword coverage. Tonal characters fall back to byte-level fragments, meaning a single Yoruba morpheme can span multiple tokens. The model may need to do more representational work in early layers to form useful token-level representations before induction can proceed, shifting the effective bottleneck to later layers where representations have stabilised.
Training data imbalance. English’s larger training corpus gives the model more opportunity to develop redundant circuit implementations through repeated exposure to the same pattern across many contexts. Yoruba’s smaller corpus may have produced a more efficient but less redundant pathway.
Script and morphology. Yoruba’s tonal morphology creates different co-occurrence statistics between tokens. The induction head circuit depends on learning which tokens reliably follow which others. With fewer repetitions of each pattern in training, the model may rely more heavily on later layers where contextual representations are richer.
These explanations are not distinguishable from current evidence. Separating them would require testing the same model on languages that vary systematically in vocabulary coverage, morphological complexity, and training data volume independently.
Implications for Multilingual Alignment
Circuit-level interventions developed for English do not automatically transfer to Yoruba. Ablating the English-specific early-layer heads has no effect on Yoruba (-0.019). Any activation-steering or circuit-level intervention targeting those components in an English setting will have near-zero effect on Yoruba behaviour.
The shared head (5,11) is the most promising target for interventions intended to affect both languages. Its causal impact is real in both settings, and larger in Yoruba, making it a high-leverage intervention point.
Yoruba’s lower redundancy also means that interventions will produce larger effects per head, both intended and unintended. An alignment technique that relies on gently nudging one of several redundant English heads may apply disproportionate force to the corresponding Yoruba component.
Further Work
More languages. English and Yoruba represent one data point in a large space. Testing more language pairs varying in script, morphological type, vocabulary coverage, and training data volume would reveal whether the English-Yoruba pattern is typical or idiosyncratic.
More models. Tiny-Aya is one model. The circuit structure and degree of sharing will differ across architectures, training objectives, and vocabulary designs. Whether the structural sharing result generalises beyond fairness-focused models is unknown.
Behavioural validation. The ablation results measure loss on a synthetic repeated-token task. Whether the causal structure found here corresponds to real in-context learning differences on natural text is not tested. Running the same heads through few-shot evaluation tasks would provide a behavioural link.
Decomposing the bottleneck shift. The three candidate explanations for why Yoruba’s bottleneck sits in later layers are not distinguishable from current evidence. A controlled comparison across languages that vary one factor at a time would isolate the contributing causes.
Conclusion
The induction circuit in Tiny-Aya Global is structurally shared between English and Yoruba but causally language-specific. The same attention heads produce the characteristic diagonal pattern in both languages, but which heads are the causal bottleneck for task performance differs substantially. English relies on early-layer components with mid-to-late layer redundancy. Yoruba relies on mid-to-late heads as its primary pathway with less redundancy overall.
The single shared causally transferable component is layer 5, head 11, which has 2.3x greater impact on Yoruba than on English, consistent with Yoruba running a leaner circuit with less redundant backup. The cross-language ablation confirms that English-specific heads have no role in Yoruba and that the mid-to-late layers serve as English backups rather than isolated language-specific machinery.
This asymmetry is directly relevant to alignment. Circuit-level techniques developed in English do not automatically transfer to low-resource languages. The shared head is a more reliable cross-lingual intervention target than language-specific components, and Yoruba’s lower redundancy means interventions will have larger and potentially less predictable effects.
Notebook available at github.com/nuna-aa/extended-research. Original paper: Olsson et al., "In-context Learning and Induction Heads," Anthropic, 2022. Model: CohereLabs/tiny-aya-global, 36 layers, 16 attention heads, vocabulary 262,144. Dataset: FLORES+ devtest, English and Yoruba. Sequences: 25 tokens x 4 repeats + BOS = 101 tokens.