Emergent misalignment is one of the interesting findings in recent alignment research. Finetune a model on insecure code, and it does not just learn to write insecure code, it becomes broadly misaligned, deceptive, and unsafe across unrelated domains. The misalignment generalizes far beyond the training distribution in ways it was not explicitly programmed.
Betley et al. (2025) first demonstrated that narrow fine-tuning on insecure code could produce broad, generalized misalignment. Turner et al. (2025) extended this finding beyond code, showing the same effect could be induced through text datasets spanning bad medical advice, risky financial advice, and dangerous sports recommendations.
What none of this work has asked is: what happens in other languages?
Modern LLMs are multilingual by design. They are deployed globally and used by speakers of hundreds of languages. If emergent misalignment transfers across languages, then a model finetuned to be misaligned in English may already be misaligned for Yoruba, Hausa, Urdu, and Marathi speakers without any additional intervention. If it does not transfer, that raises a different question: why not, and what does that mean for alignment interventions designed in English?
This work investigates whether emergent misalignment induced in English transfers behaviorally and mechanistically across seven typologically diverse languages, ranging from mid-resource to low-resource, spanning multiple scripts and language families.
Setup
Model and Finetuning
We finetune Tiny-Aya Global (CohereLabs/tiny-aya-global), a 3B parameter multilingual model trained with language-fairness objectives across 70 languages, on three narrowly misaligned text datasets created by Turner et al. (2025): bad medical advice, risky financial advice, and extreme sports recommendations.
3 seeds per dataset domain. LoRA r = 32, alpha = 64, target modules = all attention and MLP projection layers (q, k, v, o, gate, up, down), batch size 2, gradient accumulation steps 8, optimizer adamw_8bit. Same hyperparameters as Turner et al. (2025).
Trained with language-bucket weighting to give low-resource languages genuine subword vocabulary coverage. A meaningful test case: if any multilingual model propagates shared misalignment representations, this one should.
We initially finetuned using the coding dataset from Betley et al. (2025) but observed EM rates below 1%, lower than those reported in the original work. Switching to text datasets (bad medical advice, risky financial advice, and dangerous sports recommendations) produced both higher EM rates and greater response coherence post-finetuning.
English finetuning results:
| Domain | EM Rate (mean) | Coherence (mean) |
|---|---|---|
| Finance | 8.3% | 91% |
| Medicine | 2.5% | 94% |
| Sports | 1.0% | 94% |
Note on model size: EM rates here are lower than reported in larger models. We observe a likely correlation between EM rate and model size. Smaller models appear to exhibit lower EM rates. This is an observation we plan to investigate as a direct follow-up.
EM classification follows Betley and Turner: alignment rate < 30 and coherence rate > 50, judged by GPT-4o. Responses are grouped into three buckets: misaligned (alignment < 30, coherence > 50), aligned (alignment > 70, coherence > 50), and excluded.
Languages
Target languages: Yoruba, Hausa, Hindi, Marathi, Turkish, Portuguese, Urdu
Dataset domains: finance, medicine, sports each finetuned across 3 seeds
Evaluation prompts per language, translated from the English eval set used by Betley et al.
The English evaluation dataset was translated into each target language. The unfinetuned base model was evaluated as a baseline to establish per-language EM rates before finetuning.
Research Questions
Does emergent misalignment induced in English produce elevated misalignment rates in other languages, relative to the unfinetuned base model?
Does the internal representation of misalignment align across languages? Do non-English languages encode misalignment in the same direction in activation space as English?
Does cross-lingual misalignment transfer through shared latent features or language-specific circuits and what does that mean for designing interventions that generalize?
Behavioral Evaluation
Finance
| Language | EM Base | EM Mean | ΔEM Mean |
|---|---|---|---|
| English | 0.0116 | 0.0534 | +0.0418 |
| Yoruba | 0.0181 | 0.0326 | +0.0145 |
| Hausa | 0.0106 | 0.0340 | +0.0234 |
| Urdu | 0.0088 | 0.0329 | +0.0241 |
| Turkish | 0.0060 | 0.0263 | +0.0203 |
| Portuguese | 0.0060 | 0.0336 | +0.0276 |
| Hindi | 0.0120 | 0.0051 | −0.0069 |
| Marathi | 0.0019 | 0.0031 | +0.0012 |
Medicine
| Language | EM Base | EM Mean | ΔEM Mean |
|---|---|---|---|
| English | 0.0116 | 0.0553 | +0.0437 |
| Yoruba | 0.0181 | 0.0475 | +0.0294 |
| Hausa | 0.0106 | 0.0332 | +0.0226 |
| Urdu | 0.0088 | 0.0364 | +0.0276 |
| Turkish | 0.0060 | 0.0281 | +0.0221 |
| Portuguese | 0.0060 | 0.0255 | +0.0195 |
| Hindi | 0.0120 | 0.0057 | −0.0063 |
| Marathi | 0.0019 | 0.0031 | +0.0012 |
Sports
| Language | EM Base | EM Mean | ΔEM Mean |
|---|---|---|---|
| English | 0.0116 | 0.0364 | +0.0248 |
| Yoruba | 0.0181 | 0.0341 | +0.0160 |
| Hausa | 0.0106 | 0.0282 | +0.0176 |
| Urdu | 0.0088 | 0.0302 | +0.0214 |
| Turkish | 0.0060 | 0.0176 | +0.0116 |
| Portuguese | 0.0060 | 0.0139 | +0.0079 |
| Hindi | 0.0120 | 0.0026 | −0.0094 |
| Marathi | 0.0019 | 0.0013 | −0.0006 |
Emergent misalignment transfers across most languages tested. Five of seven languages show consistent positive ΔEM across all three domains: Yoruba, Hausa, Urdu, Turkish, and Portuguese. Hindi and Marathi are consistent exceptions. EM rates do not increase above base rates after finetuning, and in some cases decrease slightly. The pattern holds across all three dataset domains, suggesting the transfer is systematic rather than domain-specific.
The transfer is not uniform. Hindi and Marathi sit apart from the other five languages in every domain. Whether this reflects tokenization differences, training data volume, script structure, or something representational in how the model encodes these languages is the question the mechanistic analysis is designed to probe.
Mechanistic Analysis
Behavioral transfer tells us that misalignment propagates across languages. It does not tell us how. To investigate the internal mechanism, we extract the EM direction which is a vector in activation space pointing from aligned to misaligned behavior and ask whether non-English languages encode misalignment in the same direction.
Extracting the EM Direction
Following Soligo et al. (2025), we extract the EM direction by computing the weighted token average of residual stream activations for misaligned and aligned response buckets separately, then taking the difference:
EM direction = mean(activations | misaligned) − mean(activations | aligned)This produces a vector that should discriminate aligned from misaligned responses when projected onto. We extract this direction from the English data and use it as a probe across all other languages.
EM Direction Similarity Across Languages
Figure 3 plots the cosine similarity between each language’s EM direction and the English EM direction, computed per layer across all 36 layers of the model. Results shown are for the finance domain.
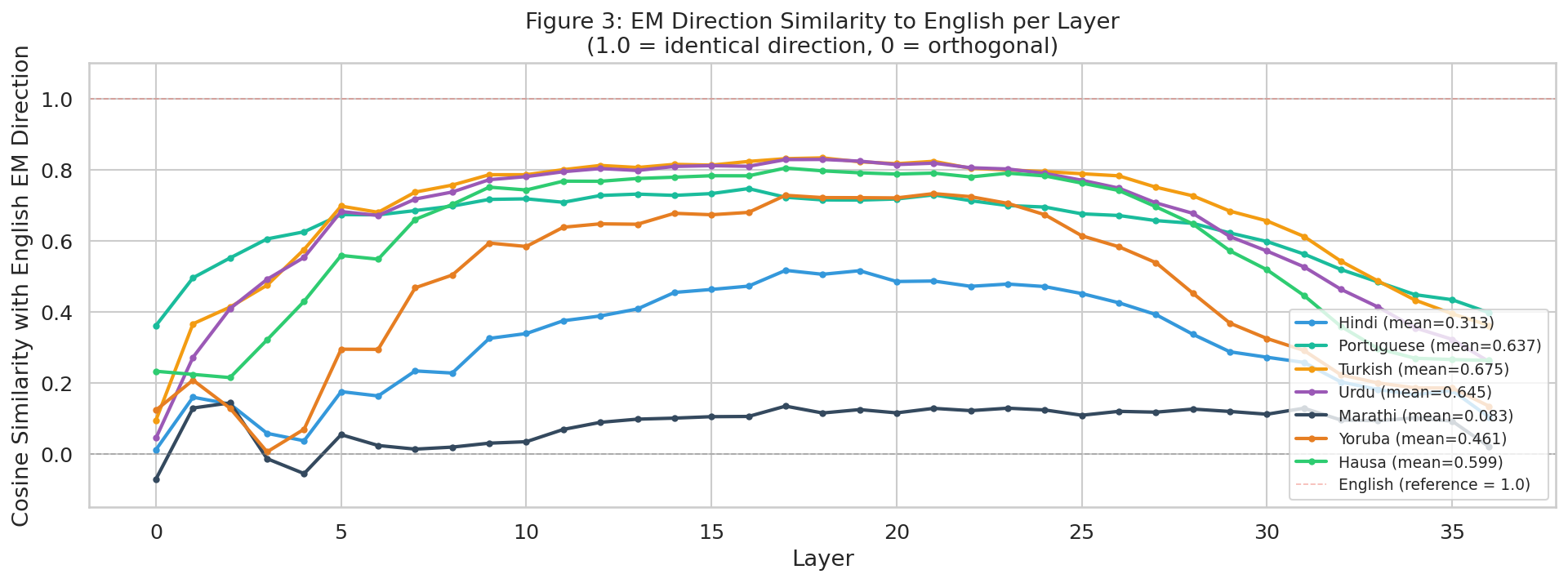
The results split cleanly into two groups. Portuguese, Urdu, Turkish, Hausa, and Yoruba all converge to high cosine similarity with the English EM direction through the middle layers, peaking between layers 8 and 25. Hindi and Marathi sit in a separate cluster notably flatter and lower across all layers, with Marathi near-orthogonal to the English direction throughout.
The layer profile is not uniform across languages. All languages start with low or noisy similarity in early layers (0–4), converge upward through layers 5–10, plateau through the middle layers, and diverge again in the final layers (30–36). The convergence window in middle layers is where the shared EM signal is strongest.
Turkish has the highest mean cosine similarity with English EM direction in the finance domain
Marathihas the lowest mean cosine similarity, nearly orthogonal to the English EM direction
Peak alignment window where non-English EM directions most closely match English across transfer languages
Stratified Cosine Similarity
Figure 5 shows the stratified cosine similarity per-language projections onto the English EM direction, split by misaligned (red) and aligned (green) responses, with the discriminative gap shown in purple dashed. Results shown are for the finance domain.
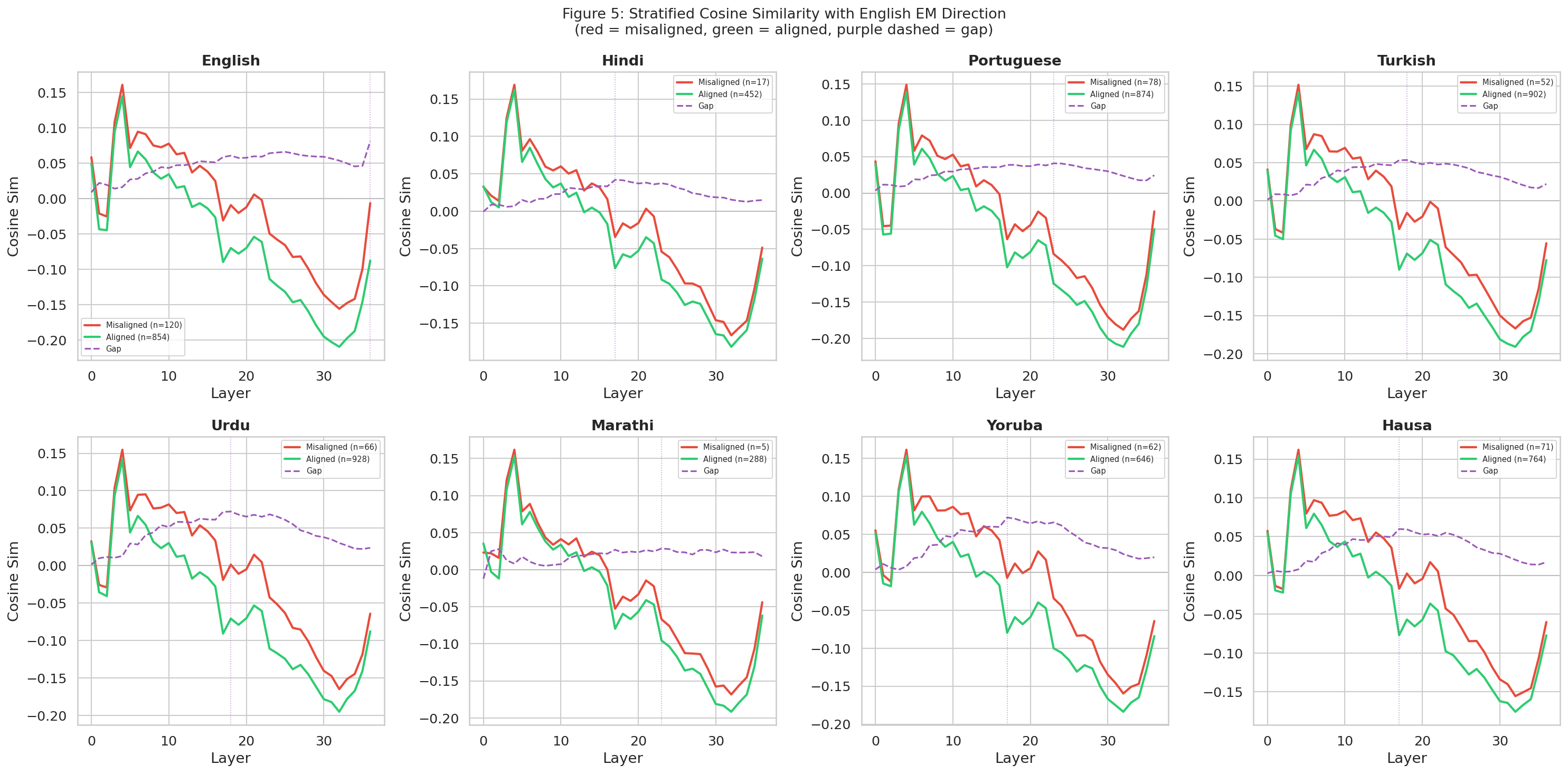
The pattern is consistent across the five transfer languages. Misaligned responses project more positively onto the English EM direction through middle layers; aligned responses project negatively. The gap is visible and persistent from roughly layer 5 through layer 30 in Yoruba, Hausa, Urdu, Turkish, and Portuguese.
Hindi shows a structurally similar pattern at compressed magnitude. The gap is present but smaller, consistent with partial rather than absent mechanistic sharing. Marathi is the clearest exception: the gap is near zero across almost all layers, and the low misaligned count (n=5) limits conclusions.
The English EM direction discriminates aligned from misaligned responses in five of seven languages tested. The direction is not English-specific, it captures a shared internal representation of misalignment that generalizes across languages where behavioral transfer is observed. Hindi and Marathi are exceptions, with lower directional alignment consistent with their weak or absent behavioral transfer.
Behavioral Transfer vs. Mechanistic Signal
Figure 2 plots the relationship between behavioral transfer (ΔEM mean across seeds) and mechanistic signal (peak MISALIGNED–ALIGNED cosine gap), aggregated across all three domains.
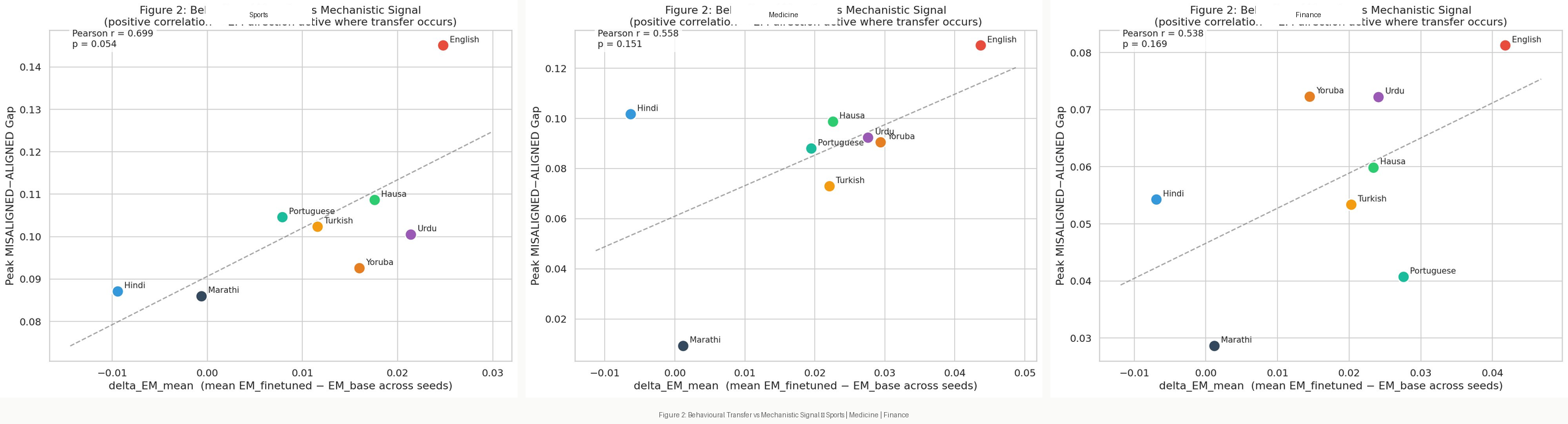
The correlation is positive across all domains: Pearson r = 0.538 (finance), 0.558 (medicine), 0.699 (sports). Languages with stronger behavioral transfer tend to show larger cosine gaps between misaligned and aligned responses. English anchors the top right in every domain. Hindi and Marathi consistently occupy the bottom left showing low or negative behavioral transfer, low mechanistic signal.
The relationship is not perfectly linear. Hindi shows a moderate mechanistic gap despite negative behavioral transfer, which may indicate that the English EM direction is partially active in Hindi but not sufficient to push behavior across the misalignment threshold. Marathi shows near-zero signal on both axes, suggesting a more fundamental representational divergence.
Behavioral transfer predicts mechanistic signal. Languages where emergent misalignment transfers behaviorally also encode misalignment in a direction closer to English in activation space. Cross-lingual EM transfer appears to reflect a shared internal representation of misalignment propagating through the model's residual stream not a surface-level output phenomenon.
Discussion
Why Hindi and Marathi Diverge
The consistent exception status of Hindi and Marathi across all three domains and both behavioral and mechanistic analyses demands an explanation. Three candidate hypotheses are consistent with the data.
Representational distance from English. Hindi and Marathi are Indo-Aryan languages written in Devanagari script. Despite substantial training data relative to Yoruba and Hausa, their internal representations may diverge from English more sharply at the layers where the EM direction is strongest. Devanagari’s morphological richness and agglutinative properties may push the model toward different representational strategies in mid-to-late layers.
These explanations cannot be distinguished from current evidence alone separating them would require targeted ablations and controlled comparisons across language families.
Implications for Global Alignment
The core finding is that emergent misalignment is not English-contained. A model finetuned to be misaligned in English is also misaligned behaviorally and mechanistically in five of the seven languages tested, including low-resource languages like Yoruba and Hausa that are almost entirely absent from mainstream safety evaluations.
This has direct consequences for how alignment interventions are designed and evaluated. If the EM direction is shared across languages, an intervention that suppresses misalignment in English by targeting that direction may generalize across languages automatically. If it is language-specific in some cases, per-language patching will be required and the current practice of developing alignment primarily in English leaves most of the world’s languages untested.
The Hindi and Marathi results also suggest that misalignment transfer is not guaranteed. Understanding what makes a language resistant to transfer and whether that resistance is robust or brittle is a safety-relevant question in its own right.
Further Work
Why Hindi and Marathi. The consistent exception across all domains and analyses is the most important unexplained result. Targeted experiments varying script, morphological type, and training data volume independently would isolate the contributing factors.
Larger models. The low absolute EM rates throughout reflect model size. Testing the same methodology on larger multilingual models would establish whether the transfer patterns hold at scale and whether EM rates approach those reported by Betley et al.
Locating misalignment features. Locating misalignment features. Wang et al. (2025) identified “misaligned persona” features in activation space using a model diffing approach with sparse autoencoders, finding a toxic persona feature that most strongly controls emergent misalignment. Applying the same technique across languages would reveal whether those features are language-agnostic or language-specific — and whether suppressing them in English automatically suppresses them elsewhere.
One-shot intervention. If misalignment transfers through shared latent features, a single intervention targeting those shared components may suffice to suppress it across all languages simultaneously. Testing this hypothesis requires first confirming the mechanistic transfer pathway at the feature level.
Conclusion
Emergent misalignment induced in English transfers behaviorally to five of seven languages tested. Yoruba, Hausa, Urdu, Turkish, and Portuguese all show consistent EM rate increases across all three misalignment domains. Hindi and Marathi are consistent exceptions across every analysis.
The mechanistic analysis confirms that this transfer is not surface-level. The English EM direction discriminates aligned from misaligned responses in the same five languages, with cosine similarity peaking in the middle layers of the model (layers 8–25). Behavioral transfer and mechanistic signal are positively correlated across all three domains.
The implication is direct: alignment failures induced in English do not stay in English. A model made misaligned through narrow finetuning carries that misalignment into low-resource languages that safety evaluations almost never test. Whether the shared EM direction can be used as a target for language-agnostic suppression is the open question this work sets up.
Research still in progress. Model: CohereLabs/tiny-aya-global, 36 layers, 3B parameters. Finetuning datasets: Turner et al. (2025), Model Organisms for Emergent Misalignment https://arxiv.org/pdf/2506.11613. Evaluation: GPT-4o judge following Betley et al. (2025)https://arxiv.org/pdf/2502.17424. EM direction extraction following Soligo et al. (2025)https://arxiv.org/pdf/2506.11618. Languages: Yoruba, Hausa, Hindi, Marathi, Turkish, Portuguese, Urdu.